- Tue 06 September 2022
In my last post I showed the basics of processing the full Wikipedia data set efficiently. That was intended to be the foundation of more complex code that could turn Wikipedia into a relational database.
What I don't plan to do is use NLP with the body text of articles. The movie Mission: Impossible - Ghost Protocol has 50kb of article text, but turning arbitrary text into fielded data with a defined schema is not within the scope of this project.
My intuition was that there's low hanging fruit of significant fielded data in Wikipedia, in the form of infoboxes. A relatively simple project should be able to extract it all, and
This is the infobox for Mission: Impossible - Ghost Protocol. Hopefully this format is largely consistent and well populated across movies. And beyond movies, hopefully corresponding infoboxes exist for everything else in the data set.
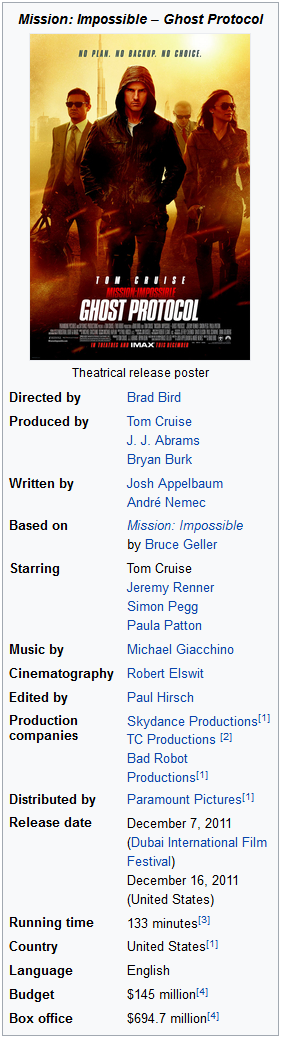
First let's do a quick check of the data gathered by the code in the previous post. Using a pyspark shell, I found there are 126,104 Wikipedia articles with a "film" infobox.
In [1]: from pyspark.sql.types import *
In [2]: schema = StructType([ \
...: StructField("id", StringType(), True), \
...: StructField("namespace", IntegerType(), True), \
...: StructField("title", StringType(), True), \
...: StructField("redirect", IntegerType(), True), \
...: StructField("timestamp", StringType(), True), \
...: StructField("infobox", StringType(), True)])
In [3]: df = spark.read.csv(output_path, schema=schema)
In [4]: df.createOrReplaceTempView("pages")
In [5]: spark.sql("""select count(*) from pages
where namespace=0 and redirect=0
and infobox='film'""").show()
+--------+
|count(1)|
+--------+
| 126104|
+--------+
Using the infobox as a proxy for the "type" of Wikipedia article, what are the most common article types?
In [6]: spark.sql("""select count(*),infobox from pages
where namespace=0 and redirect=0
and infobox is not null
group by 2 order by 1 desc""").show()
+--------+--------------------+
|count(1)| infobox|
+--------+--------------------+
| 402041| settlement|
| 219109| person|
| 159370| football_biography|
| 147737| album|
| 126104| film|
| 93402| musical_artist|
| 68717| officeholder|
| 66368| nrhp|
| 62497| song|
| 61688| company|
| 53201| sportsperson|
| 44192| television|
| 40317| book|
| 37269| french_commune|
| 36311| station|
| 33334| ship_begin|
| 33229|ship_characteristics|
| 32904| military_person|
| 32788| ship_image|
+--------+--------------------+
There's an interesting and eclectic mix of content types at the top that gives some quick insight about the makeup of Wikipedia content. The football_biography type probably refers to soccer rather than American football. The "nrhp" acronym refers to the National Register of Historic Places.
There's surely an equally interesting long tail of infobox/page types.
So far we have an interesting table of articles, but the ultimate goal is to capture the contents of infoboxes. The next step is to create the schema of the database. For each object type, what are all the columns for the table that will be created for that type?
A modification to the main function from the previous program outputs a row for every field in every infobox.
def parse_wt(row):
_id, text = row.revision
doc = wtp.parse(text or '')
output = []
for t in doc.templates:
name = t.name.replace('\n', ' ')
name = name.lower().strip()
if not name.startswith('infobox'):
continue
name = name.replace('infobox', '').strip()
name = re.sub('^([^|<]*).*', '\\1', name, flags=re.I).strip()
name = slugify(name)
if not name:
continue
output.append((name, '_instance', 1))
for arg in t.arguments:
argname = arg.name.replace('\n', ' ').strip()
argname = re.sub('(<!--.*?-->)', '', argname)
argname = slugify(argname)
# problematic length for a postgresql column. if the identifier
# is this long it's likely an undesirable edge case anyway
if len(argname) < 64:
output.append((name, argname, 1))
return output
Rather than produce the schema from this code I like to materialize the intermediate data set and do further processing in a separate program. The output of this program is three columns: the infobox name, the field name, and a constant value 1.
The next step will sum up the number of occurrences of each infobox/field so that it can be measured how frequently a field is present for articles of a certain type. I decided that the database schema should exclude columns that are only present in a small number of articles of a given type.
This next program outputs a SQL schema file:
import math
from itertools import groupby
from operator import attrgetter
from jinja2 import Template
from pyspark.sql.types import *
schema = StructType([ \
StructField("infobox", StringType(), True), \
StructField("argument", StringType(), True), \
StructField("cnt", IntegerType(), True)])
df = spark.read.schema(schema).csv(results_path)
df.createOrReplaceTempView("arguments")
sql = "select infobox, argument, sum(cnt) as cnt from arguments group by 1,2"
rows = spark.sql(sql).collect()
instance_counts = {row.infobox: row.cnt for row in rows \
if row.argument == '_instance'}
# only include infobox attributes that are present
# in at least 20% of pages for this infobox type
pruned_rows = [row for row in rows if \
row.cnt >= math.floor(instance_counts[row.infobox] * 0.20) \
and row.argument != '_instance' and row.argument is not None]
pruned_rows.sort(key=attrgetter('infobox'))
table_column_map = {k:sorted(list(r.argument for r in rows)) for k, rows in \
groupby(pruned_rows, attrgetter('infobox'))}
create_table_tmpl = Template("""CREATE TABLE "wikipedia"."{% raw %}{{ infobox_type }}{% endraw %}"
(
"infobox_id" bigint PRIMARY KEY DEFAULT nextval('seq_infobox_id'),
"page_id" bigint NOT NULL,
"page_index" int NOT NULL,
"page_title" varchar NOT NULL,
{% raw %}{% for column in columns -%}{% endraw %}
"{% raw %}{{ column }}{% endraw %}" varchar{% raw %}{{ "," if not loop.last }}{% endraw %}
{% raw %}{% endfor %}{% endraw %}
);
CREATE INDEX ON "wikipedia"."{% raw %}{{ infobox_type }}{% endraw %}" (page_id);\n\n""")
for infobox_type, columns in table_column_map.items():
print(create_table_tmpl.render(infobox_type=infobox_type, columns=columns))
At the end of this step, the output is a text file with a number of CREATE TABLE statements. The first program ran on a Spark cluster and output data to S3 because of how large the Wikipedia data set is. it was convenient for this program to run locally and print its output, and possible because it's processing a smaller intermediate data set.
Now that the tables exist, the last step would be to transform the data set into a format that can be loaded into these tables.